

APMPlus 尾采样技术的降本增效实践哈希算法原理解析,如何利用哈希函数预测博彩走势
2026-02-01哈希算法,SHA256,哈希函数,加密哈希,哈希预测/哈希算法是博彩游戏公平性的核心,本文详细解析 SHA256 哈希函数的运作原理,并提供如何通过哈希技术进行博彩预测的方法!在现代软件工程架构实践中,工程师普遍面临一个挑战:如何在海量的请求中精确捕捉异常链路,同时避免数据成本的快速增长。
本文将探讨分布式链路追踪(Distributed Tracing)中的采样(Sampling)技术,并介绍火山引擎 APMPlus 团队在尾采样(Tail-based Sampling)方面的技术实践,以期为解决上述挑战提供一种思路。
在微服务环境中,一次用户请求可能触发后台数十个服务的级联调用。为了掌握请求的全过程,分布式链路追踪技术被广泛采用。一次完整的请求链路(Trace)由多个服务站点和内部方法调用(Span)组成,所有 Span 串联起来,便构成了完整的 Trace 路径。
Trace 数据可用于计算衡量服务健康度的三大核心指标——R.E.D 指标:
在 OpenTelemetry 生态中,这些指标通常通过分析全量的 Span 数据生成。例如,SpanMetricsConnector 负责统计 Span 的数量、错误状态和耗时,从而计算出 R.E.D 指标。然而,为了保证指标的绝对准确性,理论上需要采集 100% 的 Trace 数据,这在高并发场景下会带来巨大的网络、计算和存储开销。为控制成本,必须进行采样,只保留部分代表性 Trace。
最常见的采样方法是头采样(Head-based Sampling)。该方法在链路的第一个 Span(Root Span)产生时,依据固定概率(如 1%)决定该 Trace 的所有后续 Span 是否被采集。这种方法简单直接,但存在明显缺陷:
指标失线% 的数据,再通过乘以 100 的方式推算总体指标,那么低概率出现的错误和慢请求 Trace 很容易在采样过程中被忽略。最终得到的指标可能无法真实反映服务的整体状况。
错失关键问题现场: 一个请求在开始阶段可能表现正常,但在链路末端因下游服务超时而失败。在头采样机制下,这条异常 Trace 很可能在初始阶段就被判定为“无需采集”,导致定位问题的关键线索丢失。
如何在确保 R.E.D 指标准确性、精准捕获异常链路的同时,有效控制数据采集成本,成为一个待解的难题。尾采样(Tail-based Sampling)则提供了一种新的解决思路,它允许在链路结束后,根据完整的 Trace 信息再决定是否保留。
尾采样是一种“先收集,后决策”的策略。它会等待一条 Trace 上的所有(或绝大部分)Span 都生成完毕,然后基于完整的链路信息,例如是否包含错误、总耗时是否超标、是否命中了特定的业务标签等,来做出采样决策。
在 APMPlus 中,O11yAgent 是观测数据的核心采集组件。在火山引擎的 VKE(容器服务)环境中,它由两部分组成:
O11yAgent Operator: 负责应用的自动插桩、配置动态更新、版本升级和弹性伸缩。
所有应用产生的 Traces、Metrics、Logs 数据都会汇聚到 Collector。Trace 数据除了被正常处理外,还会通过 SpanToMetrics 组件实时转换为 Metrics 数据。此设计确保了无论后续采样策略如何,总能基于全量数据计算出准确的 R.E.D 指标。处理流程如下图所示:
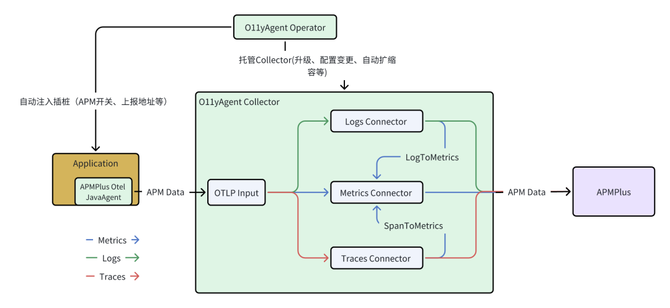
该设计的优势在于将指标计算与 Trace 采样解耦,先确保获取准确的全局指标,再决定哪些 Trace 细节值得保留以供深入分析。
尾采样面临的核心挑战是:在分布式环境下,一条 Trace 的不同 Span 可能产生于不同服务的不同 Pod 上,并被不同的 Collector 实例接收。为了对整条 Trace 进行统一决策,必须将这些 Span 聚合在一起。
我们的解决方案是基于 TraceId 的一致性哈希路由。当一个 Collector 实例收到一批 Span 后,它会根据每个 Span 的 TraceId 计算哈希值,并将该值映射到一个一致性哈希环上的特定节点(即另一个 Collector 实例的 PodIP)。然后,它会将这批 Span 转发给负责处理该 TraceId 的 Collector。通过这种方式,同一条 Trace 的所有 Span 最终都会在同一个 Collector 实例上汇合。
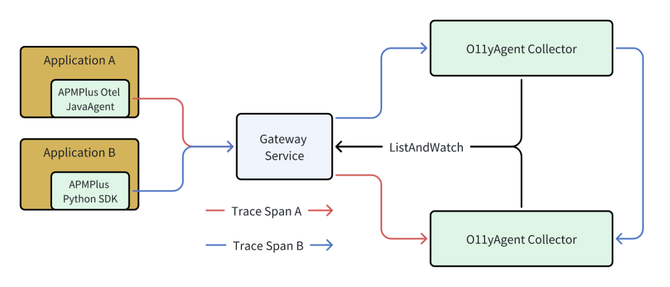
在 K8s 环境下,Pod 的 IP 会动态变化。Collector 通过 ListAndWatch 机制实时感知集群中其他 Collector 节点的增删,动态维护一致性哈希环,从而保证了路由的健壮性。
当一个 Collector 收集完一条 Trace 的所有 Span 后,便进入采样决策阶段。在实际业务中,采样需求是多维度的:
环境策略: 生产环境(prod)的采样率需要低于测试环境(staging)。
服务策略: 核心服务(如:订单服务)需要 100% 采集所有错误和慢请求。
为满足这些复杂需求,我们设计了多级采样机制。用户可以定义多个采样策略,并为其设置优先级和匹配规则。当一条 Trace 等待决策时,系统会:
如果所有策略都不匹配,或 Trace 等待超时,则执行一个全局的默认策略。
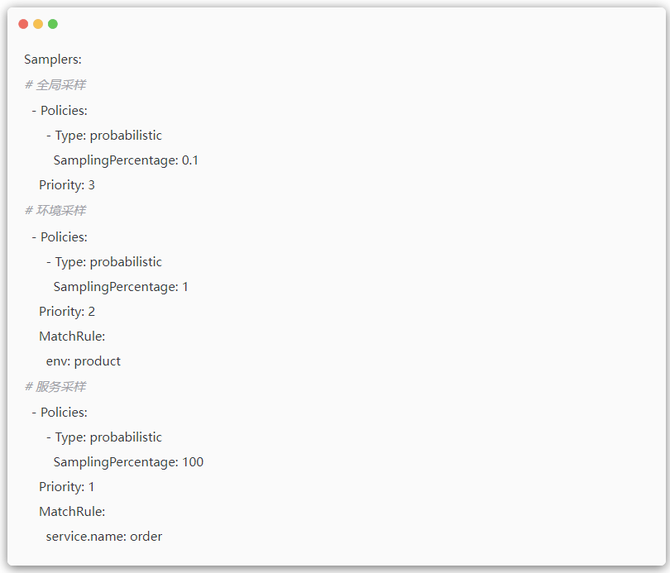
这些策略可以任意组合。一个典型的配置是:“采集所有错误 Trace,或所有慢 Trace,或 1% 的正常 Trace”。只要满足任意一个条件,该 Trace 就会被保留。
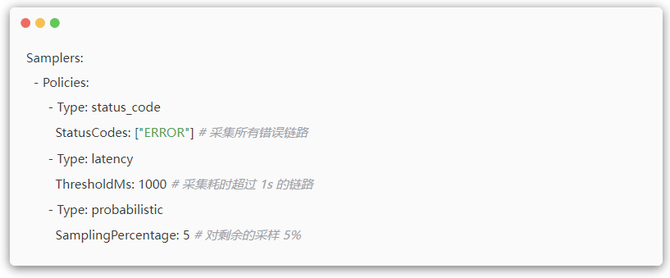
尾采样需要缓存 Span 并等待 Trace 结束,这会消耗内存和 CPU。为应对此挑战,我们实施了一系列优化措施,目标是在多数场景下将资源开销控制在与不采样时相近的水平。
决策前置 (Decision Preponement): 在同步调用场景下,Root Span 通常是最后一个到达 Collector 的。一旦收到 Root Span,即可认为该 Trace 的主干部分已完整,此时便可立即进行采样决策,无需等待超时窗口(例如 30 秒)结束,从而显著减少 Span 在内存中的缓存时间。
快速采样 (Fast Sampling): 如果采样策略中只包含“概率采样”,处理流程可以简化。由于概率采样的哈希算法(使用 FNV)对同一 TraceId 多次计算的结果是确定的,因此无需缓存 Span。每当一批 Span 到达时,直接对每个 TraceId 进行哈希计算,即可确定其是否应被采样,然后直接发送至下一处理环节。此模式下,资源开销极低。
采样结果缓存 (Decision Caching): 如果一条 Trace 因包含错误 Span 而被决策为“采样”,我们会缓存该决策结果(TraceId - Sampled)。当后续属于该 Trace 的异步 Span 或因网络延迟而“迟到”的 Span 到达时,系统可直接根据缓存结果进行处理,无需重复执行决策逻辑。这既保证了链路的完整性,也避免了不必要的计算开销。
为了避免尾采样系统成为一个不易排查问题的“黑盒”,我们在采样器的每个关键环节都嵌入了监控指标,例如:
通过这些指标,我们可以清晰地了解尾采样器的工作状态,从而快速定位“Trace 未被采集”等问题。
我们在受控环境(4核 CPU, 4GB 内存)下对尾采样能力进行了性能压测。结果如下:
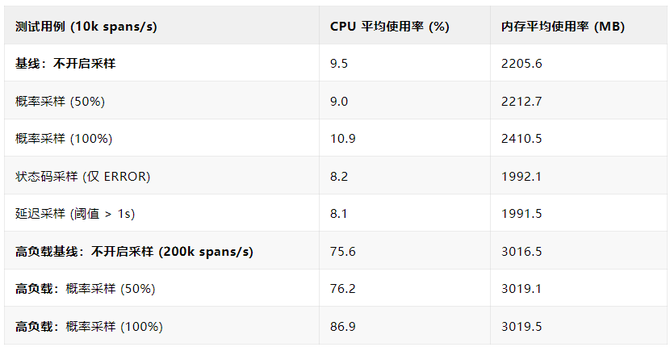
开销可控: 在常规负载下,启用尾采样带来的额外资源开销很小。在某些场景下(如仅进行状态码采样),由于提前丢弃了大量正常数据,其资源消耗甚至低于不采样的基线。
智能策略效率高: 精准采样策略(如“只采集错误或慢请求”)在大部分请求正常的情况下,几乎不增加额外负担,可以用较低成本捕获高价值的异常信息。
高负载下表现稳定: 在 200k spans/s 的高压场景下,尾采样系统表现稳定,内存占用保持平稳,证明了相关优化措施在控制缓存大小和防止内存泄漏方面的有效性。
尾采样的适用边界: 尾采样能显著提升捕获关键 Trace 的能力,但它并非适用于所有场景。对于包含大量 Span(例如数万个)的超长链路,尾采样可能带来的内存压力仍需进行评估。
头采样与尾采样的结合: 在某些流量极高的边缘服务上,可以考虑采用“头采样+尾采样”的二级采样架构。在最前端通过头采样削减大部分流量(例如,保留10%),然后再对这10%的数据进行精细化的尾采样。
回到最初的问题:如何在保障 R.E.D 指标准确性、提升问题定位效率与控制资源开销之间取得平衡?
APMPlus 的尾采样实践为此提供了一种解决方案。它通过“先计算指标、后智能采样”的模式,在保留100%的错误、慢速等高价值链路的同时,将无效数据的采集成本降至较低水平。该方案已在火山引擎内部及多个外部客户的生产环境中得到应用,在提升问题排查效率和成本节约方面取得了实际效果。
以尾采样为代表的智能采样技术,是未来大规模分布式系统可观测性体系中的一个重要发展方向。
